大多数个性化搜索体验都是谎言
了解真正的搜索个性化是什么样子——以及如何在没有臃肿、无效解决方案的情况下实现它。

我们被赋予了一个激动人心的梦想——但它并未完全达到预期。
随着人工智能的快速发展,谷歌等大公司承诺彻底改变我们发现信息的方式。
搜索本应变得更快、更智能、更符合我们的需求。
然而,我们仍然在无关的建议和一刀切的推荐中挣扎。
个性化搜索?也许更像是个性化猜测。
那么,哪里出了问题?让我们一起探讨一下。
大多数“个性化”搜索体验的实际表现
每朵玫瑰都有刺,个性化搜索引擎也是如此。
以“定制”之名销售的往往只是一种简单的数据检索。
即便如此,你也很可能找不到你想要的东西。
为什么会这样?
以下是一些原因:
原因一:固定的词序
个性化搜索引擎通常遵循硬编码的词序,预先决定了最终结果。
Prozis 电商公司的搜索引擎就依赖此规则来搜索产品。
例如,如果我们搜索“生酮饮食坚果酱”,结果会按“榛子酱”、“开心果酱”和“杏仁酱”的顺序排列。
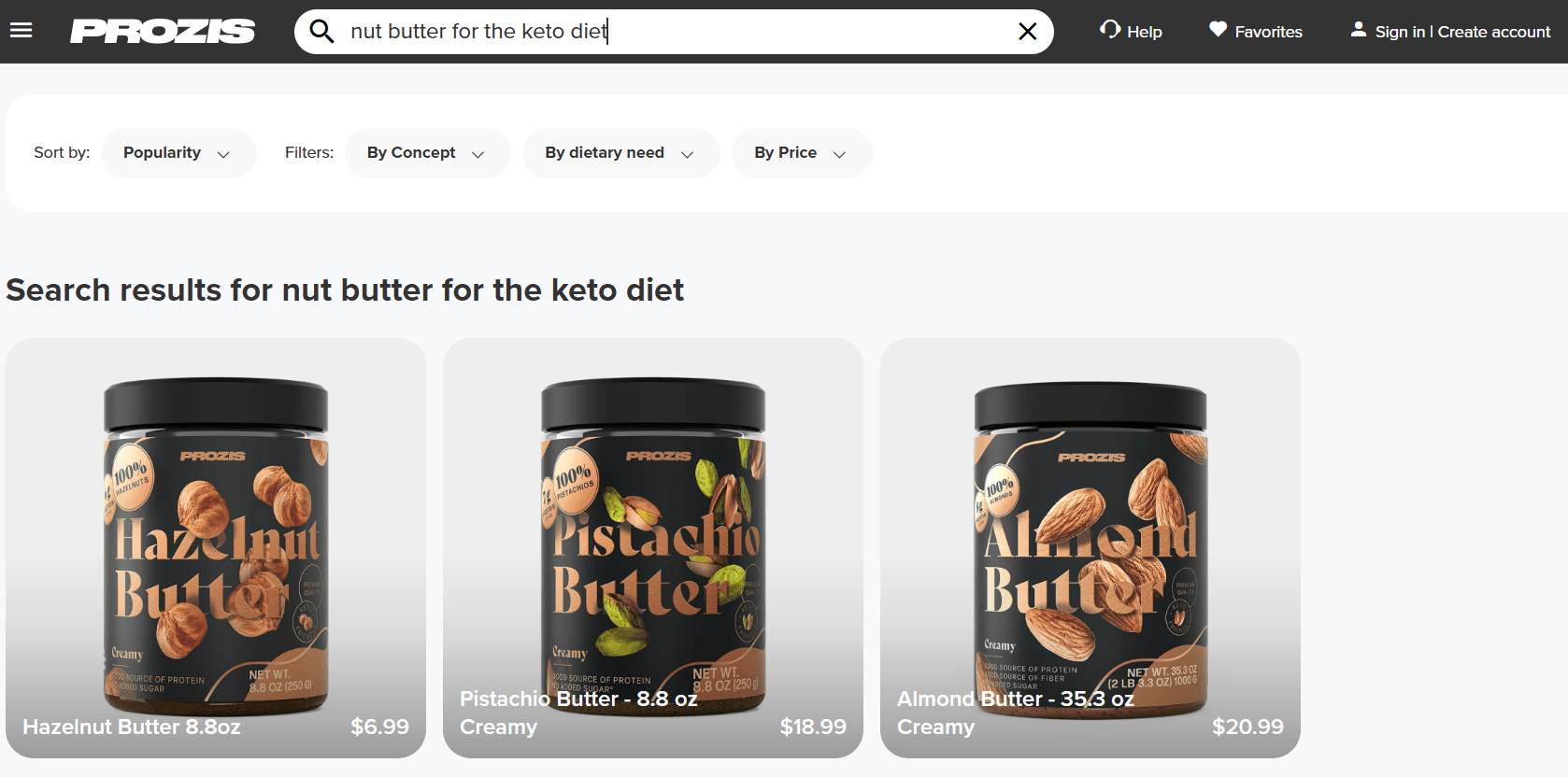
图片来源:Prozis
但问题来了。
榛子酱和开心果酱分别排在第一和第二,它们不适合生酮饮食,而真正的生酮杏仁酱却排在第三。
你在这里看到的是相关性排序。
词语的顺序预先决定并优先显示与查询密切匹配的搜索结果。
然而,在这种情况下,关键的用户意图缺失了。
我们列表中的下一点也是关于同样的问题。
原因二:孤注一掷
通常,阻碍个性化搜索的并非词序。
而是过于简化的用户细分。
个性化搜索引擎经常将用户归入宽泛的类别(例如,“科技购物者”、“户外爱好者”)。
老实说,这样更容易。
然而,我们得到的结果却是不准确和无关紧要的推荐。
毕竟,万事皆有细微差别。比如说,两个人都是户外爱好者;一个人喜欢徒步,另一个人却讨厌徒步,更喜欢豪华露营。
他们都属于同一群体。但他们真的相同吗?
流媒体服务也存在这个问题,而Netflix就是一个很好的例子。
注册时,您必须选择三部您喜欢的电影/电视节目。
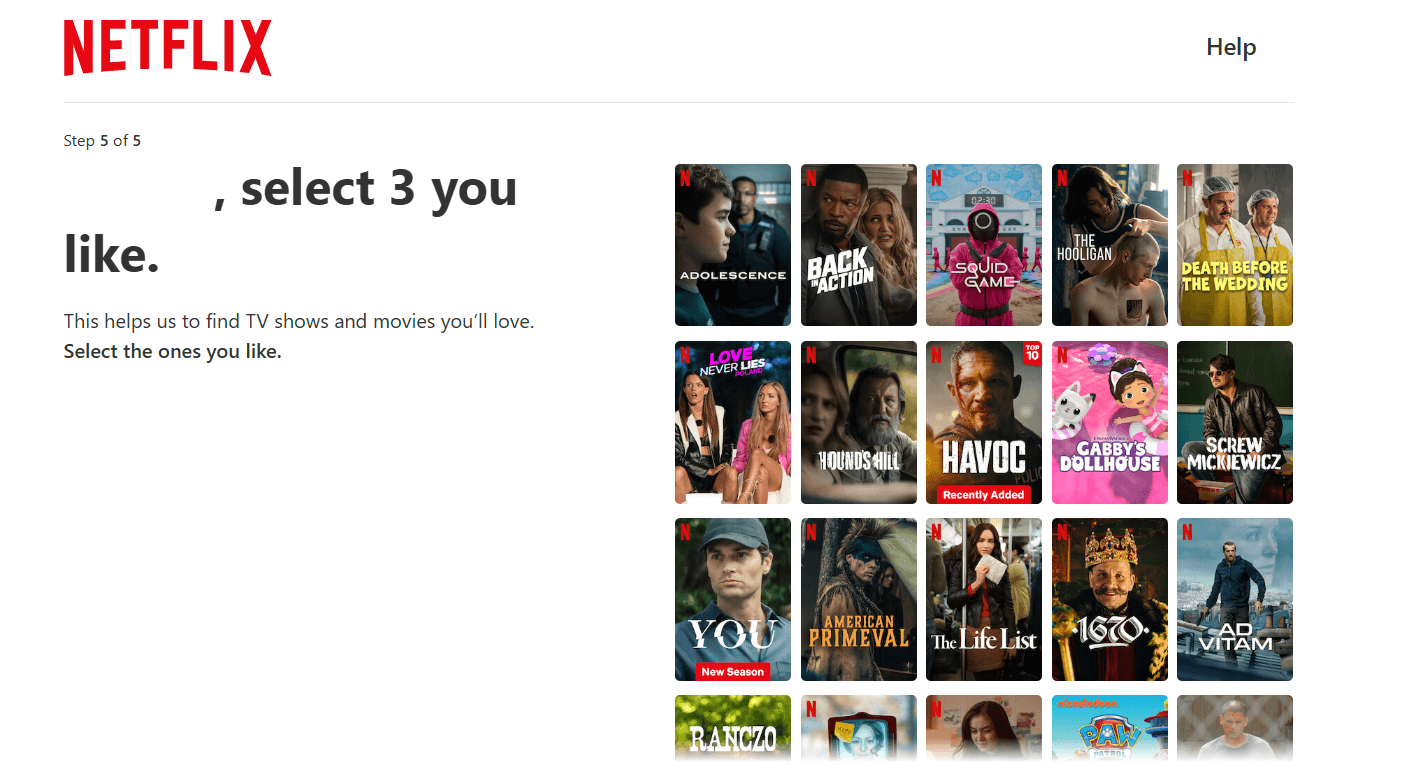
图片来源:Netflix
如果你选择医疗剧和关于法律与执法的系列剧,猜猜你会得到什么。

图片来源:Netflix
但这三部剧真的能反映你*所有*的观影偏好吗?
几乎不可能。
是的,你可能喜欢一些关于执法的节目,但你也可能讨厌看犯罪剧《嗜血法医》,因为它太血腥了。
不过,这还不是全部。
如果你仔细观察上面图片中推荐的节目,你会发现其中一些已经存在了一段时间(例如《豪斯医生》、《越狱》或《金装律师》),你可能已经看过了。
因此,Netflix 的算法也存在过滤气泡效应,这意味着你除了已经接触过的内容之外,不会接触到任何其他内容。
原因三:金钱至上
个性化意味着优先级。
在我们的案例中,是用户搜索意图及其兴趣的优先级。
大多数搜索引擎声称它们尊重这一优先级。
但它们首先要履行对广告商的义务。
许多在线市场都遵循这一逻辑,速卖通就是一个很好的例子。
当您搜索产品时,该平台会为您提供各种选项,但在此之前,它会先显示两行付费广告。
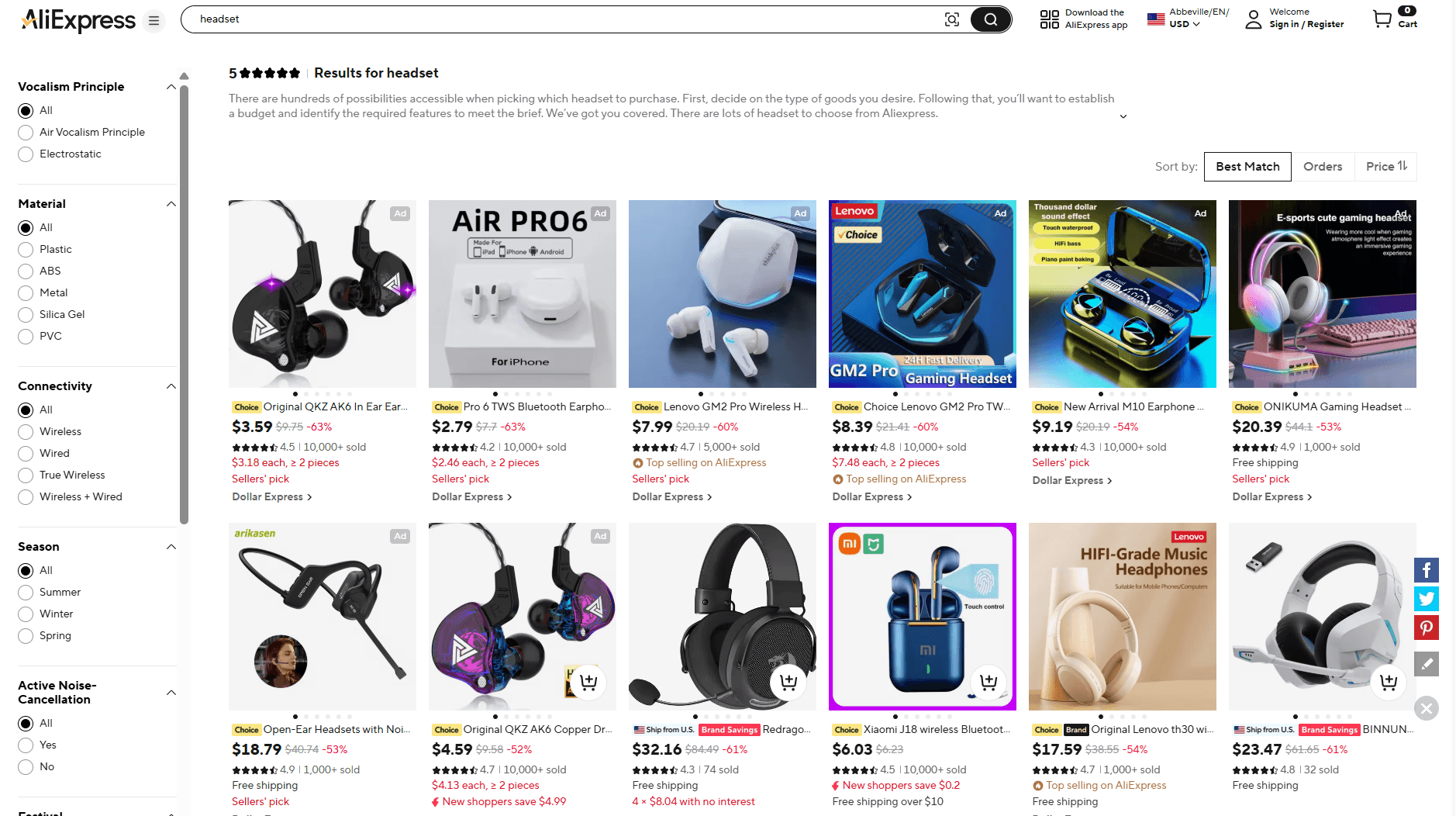
图片来源:速卖通
公平地说,像速卖通这样的市场需要与广告商合作才能维持其业务。
然而,用广告淹没搜索结果与速卖通在其主页底部声称的“为您量身定制的精选产品”相矛盾。
你不能指望用户在滚动浏览几行广告后,还会对产品推荐感到满意。
这根本不是个性化的意义所在。
什么是真正的个性化?
答案看似简单:个性化是深入理解用户需求。
当然,实际情况要复杂得多。
个性化搜索最大的障碍是分析海量用户数据,以提供最相关的搜索结果。
品牌和市场严重依赖人工智能来完成这项任务,但这并非总是答案。
毕竟,速卖通利用人工智能实现搜索结果个性化,但其系统远非完美。
人工智能可以成为个性化搜索结果的坚实基础,但这个基础只有建立在以下五个支柱之上才能保持其完整性。
支柱一:基于意图的个性化
个性化发生于用户和服务提供商之间建立起完整的默契之时。
在我们的案例中,建立这种默契(因为搜索引擎是机器)的关键在于自然语言处理,即NLP。
NLP算法使用语义网络模型来理解用户意图,从而实现个性化。
它是如何运作的?
本质上,语义搜索旨在理解词语背后的上下文,并分析结构化数据以理解查询的语义含义。
亚马逊的 A9 搜索引擎可能是这个模型实际运作的最佳范例。
我们以关键词 *book emotional intelligence toddler* 为例。
这里的关键词是toddler(学步儿童),这意味着我们不是在搜索成人情绪智力指南。
搜索引擎捕捉到这一点,并准确地分享我们所需要的内容:几本适合儿童阅读的书籍选项。
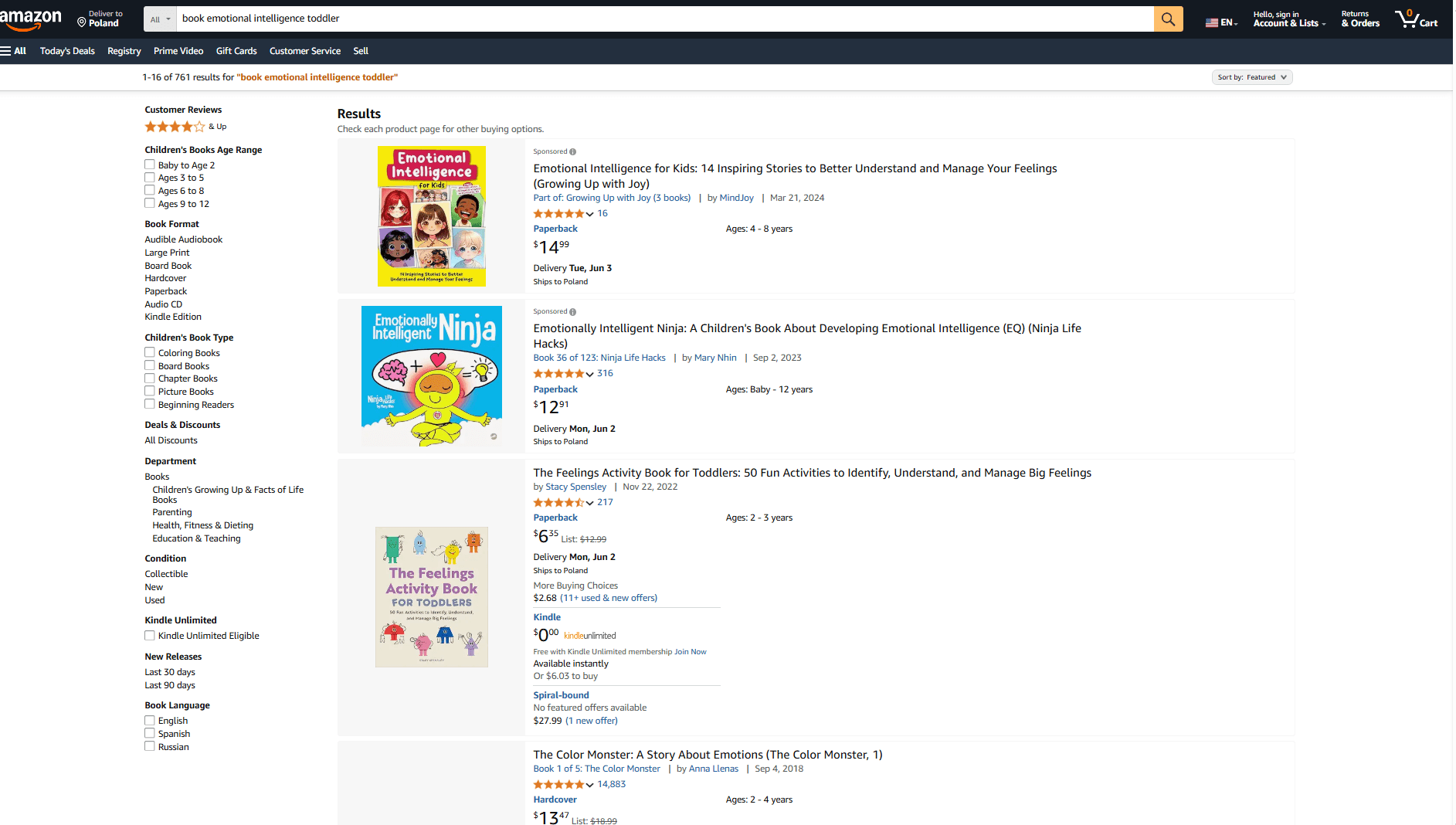
图片来源:亚马逊
我们还测试了之前关于花生酱的例子,亚马逊的搜索引擎只给出了生酮友好型产品作为最佳结果。
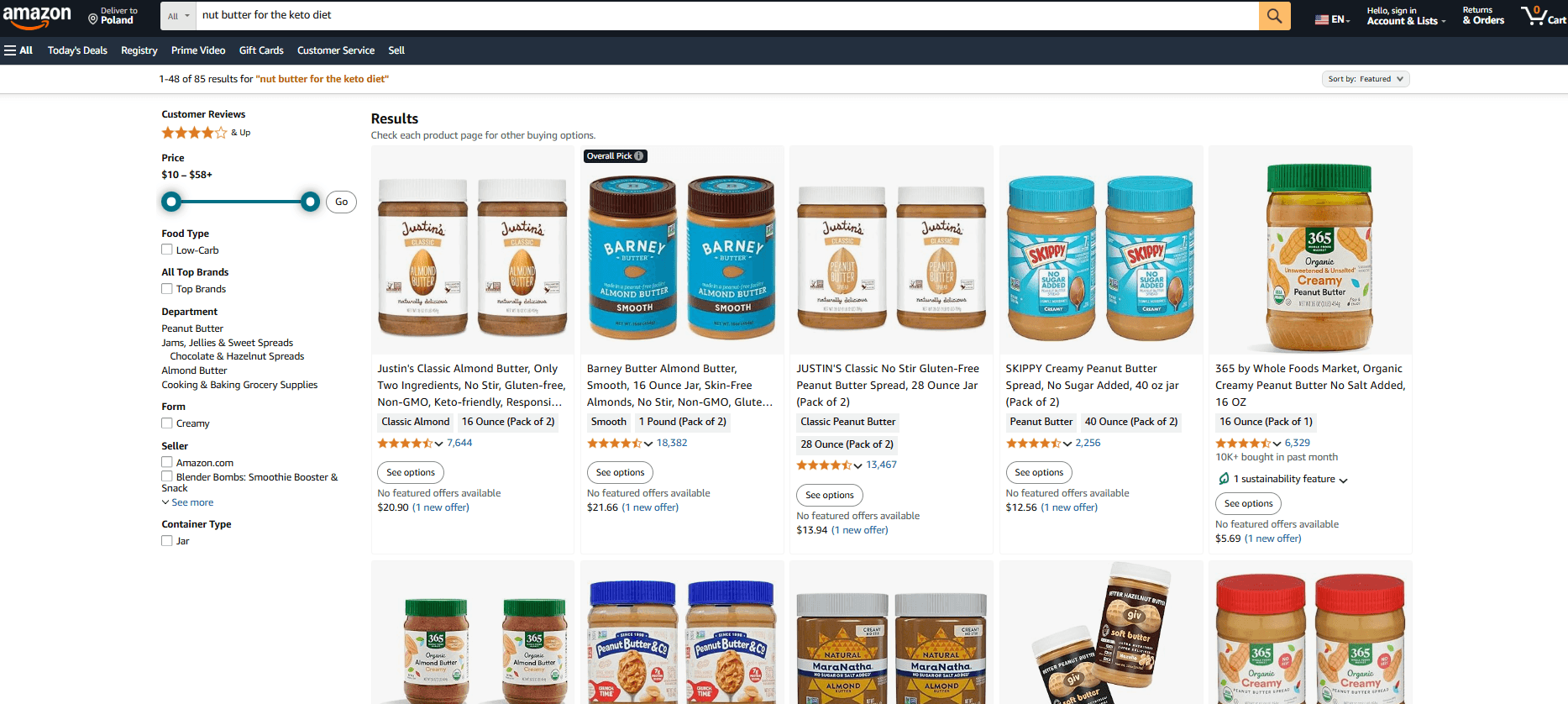
图片来源:亚马逊
但是,如果你的查询中有错别字,你还会得到个性化推荐吗?
我们接下来讨论这个问题。
支柱二:错别字容忍
仅仅因为打错字而不得不重新输入查询并得到错误结果,这绝不是一个愉快的体验。
搜索引擎使用潜在语义索引方法来检索信息,以最大限度地减少此类情况。
LSI 对错别字具有鲁棒性,因为它依赖语义理解来理解隐藏的概念。
这正是您所需要的,尤其是当您提供广泛的产品时。
Minipouce就是一个很好的例子。
下面,我们故意在“ring”这个词中打错了一个字,但仍然得到了相关的结果。
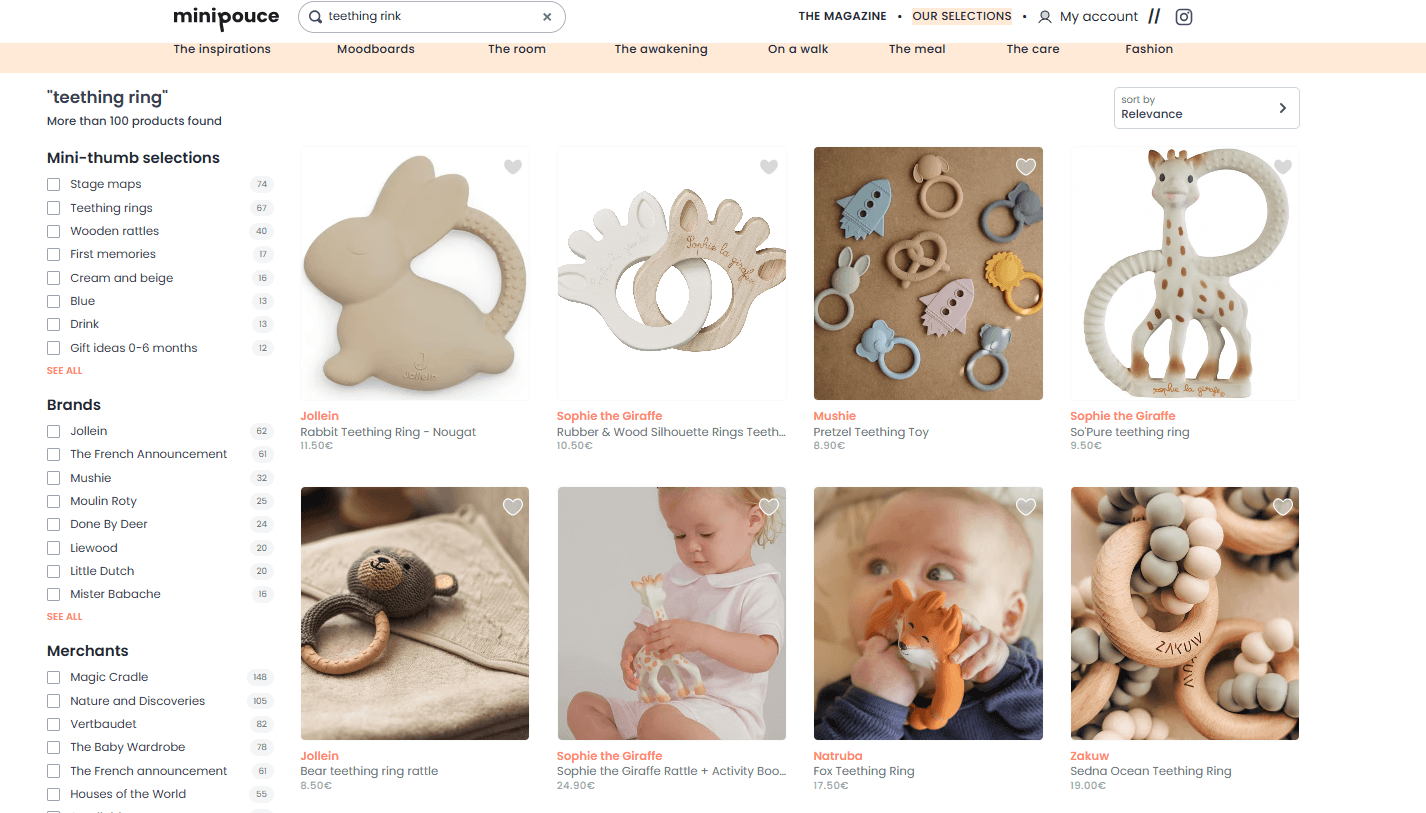
图片来源:Minipouce
该公司目录中有许多产品的名称相似,这只会增加出现错别字的可能性。因此,Minipouce 使用了 Meilisearch 的开源版本,以每次都优化产品搜索,获得相关结果。
支柱三:实时自适应学习
查询结果应该在用户与搜索引擎的交互过程中动态变化,而不是仅仅依赖静态过滤器。
为什么?
任何形式的互动都不是静态的。
用户在搜索合适的产品或信息时,其偏好和行为可能会发生变化,真正的个性化必须考虑到这一点。
因此,搜索引擎采用实时自适应学习至关重要。请看下方由 Meilisearch 提供支持的搜索引擎如何运作。
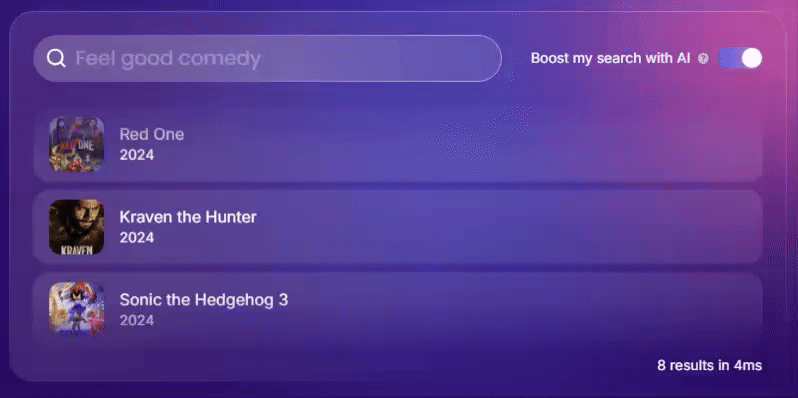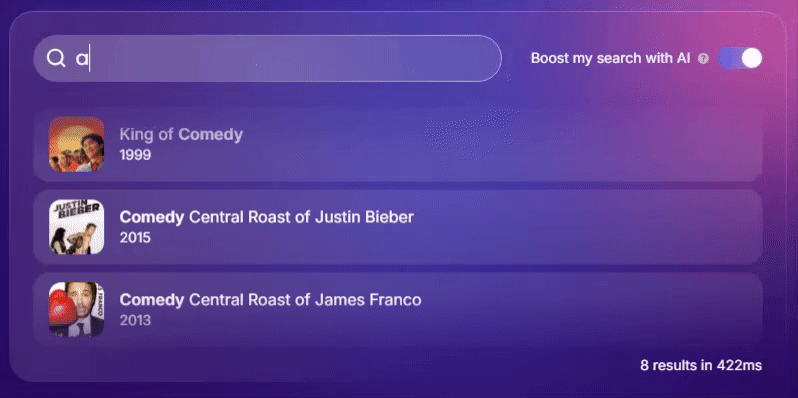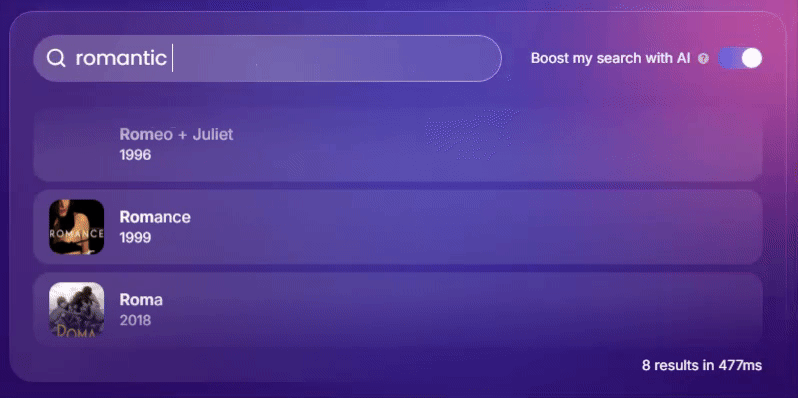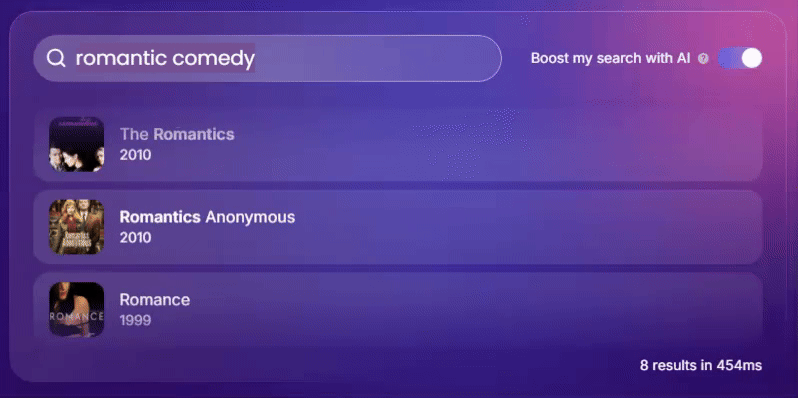
它是如何运作的?
这是一个复杂的过程,但我们可以将其分解为三个主要步骤:
- 收集和分析用户数据。搜索引擎首先收集用户搜索和相关交互的信息,为未来的个性化奠定基础。
- 调整算法。收集到的数据及其分析会影响排名、相关搜索和其他搜索算法元素,从而根据特定意图提供结果。
- 调整结果。随着用户与搜索引擎的进一步互动,搜索引擎会调整其行为,生成并优先显示相关结果,以适应用户不断变化的偏好。
当然,用户行为并不是影响搜索结果相关性的唯一因素。
搜索引擎处理的内容也至关重要。
因此,它使用的信息检索方法也同样重要。
我们接下来讨论这个问题。
支柱四:正确的信息检索方法
信息检索 (IR) 指的是查找和检索相关数据的过程。
这个过程包含三个步骤,如下所示。
- 第一步:分析非结构化数据,如网页和文本文档。
- 第二步:索引数据使其结构化,然后处理查询以匹配索引。
- 第三步:根据相关性对查询结果进行排序。

您已经熟悉一些 IR 方法,例如前面提到的 LSI。
而且,您可能已经注意到,它们对内容的解释方式略有不同。
语义搜索侧重于查询的意图和上下文含义,这使其特别适合网络搜索。
LSI 是语义搜索的一种变体,它能在单词和文档中发现隐藏的概念。因此,它非常适合文档聚类等任务。
还有一种是神经网络搜索,它采用深度神经网络 (DNN) 来理解搜索查询背后的上下文。
神经网络搜索的复杂性不同于上述方法。它以更细致的层面探索上下文关系,这使其更适用于涉及对话式查询的搜索引擎。
还有混合搜索,它是上述所有模型的结合,常用于增强型信息检索系统。
这些信息检索方法在实际生活中还有哪些用途?
这里有一些建议。

当然,这些只是少数几个例子,因为信息检索可以有更多的应用。
但有一点将它们都联系在一起。
无论搜索引擎使用何种信息检索,它都涉及到个人用户数据。
这就引发了隐私问题。
接下来我们来谈谈这个问题。
支柱五:尊重隐私
众所周知,人工智能驱动的搜索引擎依靠机器学习来提供最准确的结果。
这当然意味着它们会分析数百万次搜索的数据,并且必须检查用户数据。
但是,如何在提供顶级个性化功能的同时,确保隐私得到维护呢?
以下策略有助于完成这项工作。
- 数据加密:通过静态和传输中加密来保护数据免受第三方侵害。
- 访问控制:引入多重身份验证和基于角色的权限。
- 有限数据共享:规范与第三方的数据共享。
- 联邦学习:训练AI从新的系统更新中学习,而不是从原始用户数据中学习。
- 有效匿名化:通过隐藏个人身份信息来防止用户去匿名化。
当然,关键在于请求用户许可使用他们分享的任何数据,如果他们后来改变主意,则让他们完全控制其信息的处理方式。
为个性化搜索奠定坚实基础
真正的个性化不仅仅是提供*看起来*定制化的结果。
大多数所谓的个性化搜索之所以失败,是因为它们优先考虑静态逻辑、广泛的细分和广告商的利益,而不是用户意图。
但并非一切都已失去。
将个性化建立在自然语言处理的基础上,使用正确的信息检索方法,最重要的是,尊重隐私,是提供真正重要的搜索体验的关键。


