掌握 RAG:使用 Meilisearch 的混合搜索释放精确度和召回率
了解如何使用 Meilisearch 的混合搜索功能,通过检索增强生成 (RAG) 提高 LLM 的准确性。减少幻觉并提高搜索相关性。

我们都惊叹于大型语言模型(LLM),如ChatGPT、Gemini或DeepSeek的能力,见证了它们生成连贯且通常富有洞察力的文本的能力。然而,在这种力量的同时,我们也遇到了它们的局限性,特别是它们“幻觉”或生成不正确信息的倾向。这并不是因为它们被设计用来存储事实,而是因为它们经过训练,基于海量文本中的模式预测下一个单词,依靠的是一种“肌肉记忆”而非事实知识库。
幻觉和有限上下文的问题
许多已知案例表明,这是一个需要解决的问题。其中一个真实世界的例子是,律师仅依赖LLM,在法庭上提出了虚假的案例引用,结果发现LLM提供给他们的所有信息都是假的。这突显了LLM访问和准确引用外部可靠信息的关键需求。
那么,重复出现的问题是:我们如何利用LLM的强大功能来处理我们自己的领域特定或业务特定数据?
将LLM与特定数据连接的一种方法是直接在提示中为其提供上下文。这是一种很好的方法,尽管它只能走这么远。虽然像谷歌的Gemini这样的模型越来越能够处理更大的上下文,但LLM在一个提示中有效处理和利用的信息量是有限的。
另一种方法是微调,即在您的特定数据集上进一步训练LLM。这也非常有用,但不幸的是,微调是资源密集型的,需要大量时间和数据,这使得它不适用于频繁更新的信息。
解决方案:检索增强生成(RAG)
解决这些挑战最有效的方案是检索增强生成(RAG)。简而言之,RAG告诉模型:“在你开始说话之前,先在这些文档中搜索答案,然后再开口。”将RAG想象成给你的LLM配备了图书管理员的技能,并让它能够访问一个全面的图书馆(你的知识库或数据库)。LLM不再纯粹根据其训练数据生成响应,而是首先从你提供的来源中“查找”相关信息,然后利用这些信息来形成一个有根据的答案。这个过程不仅提高了响应的准确性,还允许LLM提供来源,直接解决了幻觉问题。
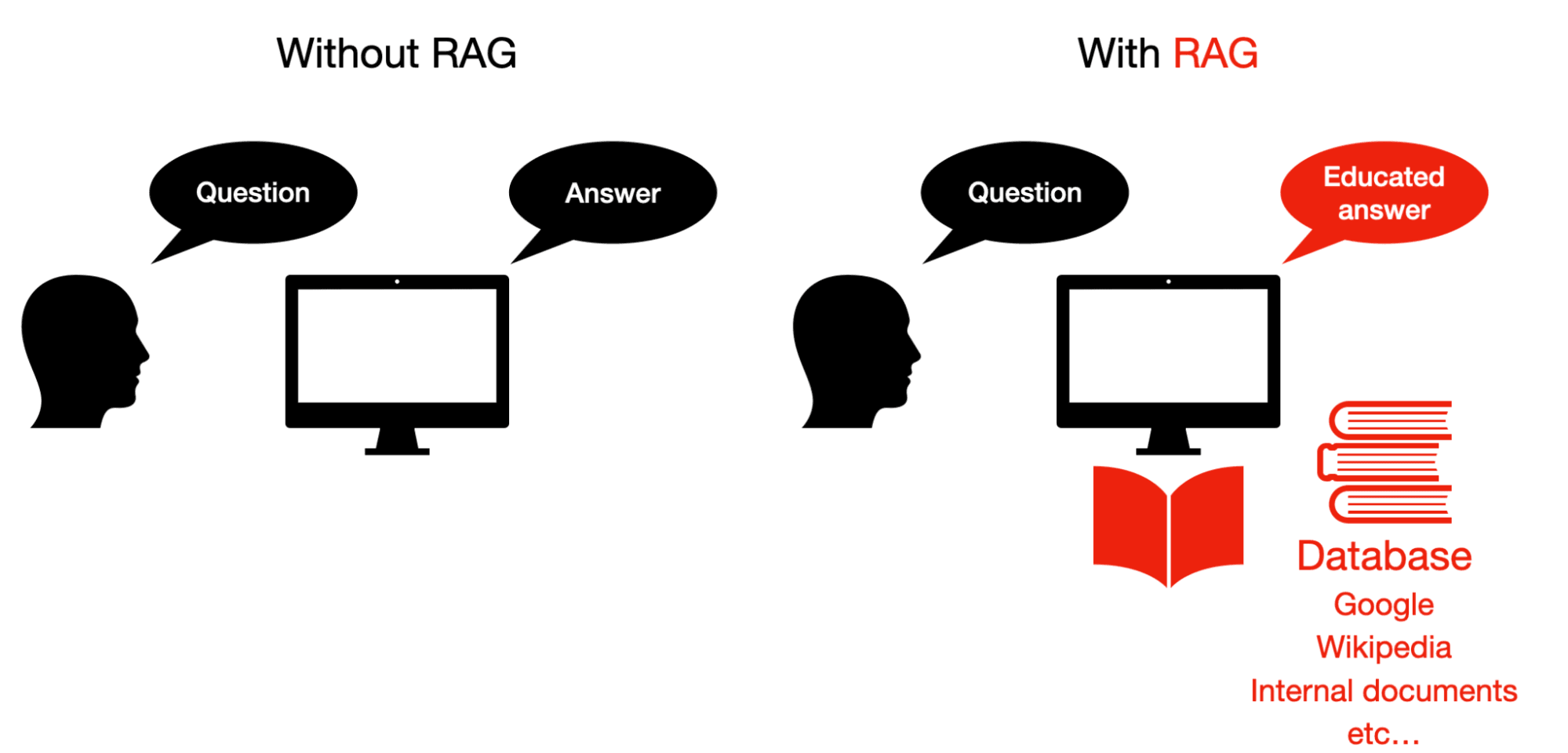 图1:通过RAG,模型将首先在数据库中搜索用户查询的答案,然后利用查询和检索到的文档来生成响应。
图1:通过RAG,模型将首先在数据库中搜索用户查询的答案,然后利用查询和检索到的文档来生成响应。
RAG工作流程通常包含三个关键步骤
- 查询转换:用户的查询被优化为有效的搜索查询。
- 信息检索:转换后的查询用于在数据库中搜索相关信息。
- 响应生成:检索到的结果以及原始提示被输入LLM以生成知情响应。
举例来说,如果用户查询是“嗯,我正在寻找巴黎最好的餐馆,有什么建议吗?”,一个好的查询转换模型(步骤1)会将其转换为“巴黎的餐馆,质量最高”。信息检索系统(步骤2)将返回一份文档或链接列表,其中包含巴黎几家餐馆的名称和评分。然后LLM将使用修改后的查询和餐馆列表来形成口头响应(步骤3)。这样想,想象你的朋友打电话问你巴黎的好餐馆。你首先将他们的问题转化为Google查询,在Google中搜索,查看前4或5个结果,然后用一两句话回复他们,根据你找到的推荐给他们。这正是RAG过程。
虽然许多人将RAG与向量数据库和检索后的独立重排序步骤关联起来,但Meilisearch等解决方案通过集成整个工作流程和堆栈来简化此过程。本博文将重点关注关键的第二步(如何正确搜索),而下一篇博文将更深入地探讨整个RAG管道,并探讨Meilisearch如何简化其部署和维护。
工具:全文搜索和语义搜索
在文本数据库中进行有效搜索对于成功的RAG至关重要。两种主要方法脱颖而出
两全其美的方法是
- 混合搜索,顾名思义,它结合了全文搜索和语义搜索的优点。在深入探讨如何结合它们之前,我们先来看看每种方法何时表现出色。
何时语义搜索更优?
当单词的组合意义比单个关键字匹配更重要时,语义搜索会大放异彩。考虑查询“预订旅行”。
- 一篇名为“关于旅行的书籍”的文章可能会因为关键字重叠而被全文搜索高度排名,但这可能不是用户想要的结果。
- 一篇名为“与我们一起安排您的旅行”的文章在语义上更相关,即使它共享的精确关键字更少。语义搜索会优先考虑后者,提供更好的结果。
何时全文搜索更优?
当您需要精确的关键字匹配时,特别是对于技术术语或特定标识符,全文搜索更具优势。例如,如果您的查询是“ISO 9001认证流程”
- 一篇名为“ISO 9001:2025认证清单”的文章因其特定的术语而完美匹配。
- 一篇名为“如何实现质量管理合规性”的文章在语义上可能相似,但缺乏直接的关键字特异性。
在语义相似性不等于正确答案的情况下,全文搜索也很有价值。例如,如果问题是“苹果是什么颜色?”,语义搜索可能会返回“橘子是什么颜色”作为最相似的句子。虽然相似,但它没有提供原始问题的直接答案。
如何结合结果:混合搜索评分
一旦我们从全文搜索和语义搜索中获得了结果,挑战在于如何有效地将它们结合成一个统一、公平的排名。Meilisearch通过根据相关性分配和组合分数来解决这个问题。
对于语义搜索,分数直接基于相似度。相似度是一种度量,对于密切相关的文本段落,其值较高;对于不相关的文本段落,其值较低,直接反映了结果与查询在概念上的匹配程度。例如,句子“你好吗?”和“嗨,过得怎么样?”之间的相似度很高。句子“你好吗?”和“我喜欢苹果”之间的相似度很低。
对于全文搜索,RAG方法通常采用传统的算法,如BM25或TF-IDF来计算每个文档的相关性得分,反映其关键字与查询的匹配程度。另一方面,Meilisearch采用另一种算法,一种称为桶排序的算法。
此过程涉及根据一组定义的排名规则(例如相关性得分、拼写错误数量或单词邻近度)将文档组织到逐渐变小的“桶”中,每个后续规则充当决胜局,直到实现精确的顺序。
Meilisearch 方法的一个关键方面是标准化这些分数。全文搜索和语义搜索的初始分数通常具有不同的范围。例如,BM25 分数可能在 0 到 1 之间,而语义相似性分数可能集中在 0.5 到 0.8 这样更窄的范围内。为了确保可比性,语义搜索分数会被拉伸和居中(这个过程称为仿射变换),使它们与全文搜索分数一样处于 0-1 范围(图 2)。这种标准化确保了两种搜索结果的一致性,从而实现统一的相关性分数。换句话说,这使得两种搜索方法的结果能够公平竞争。
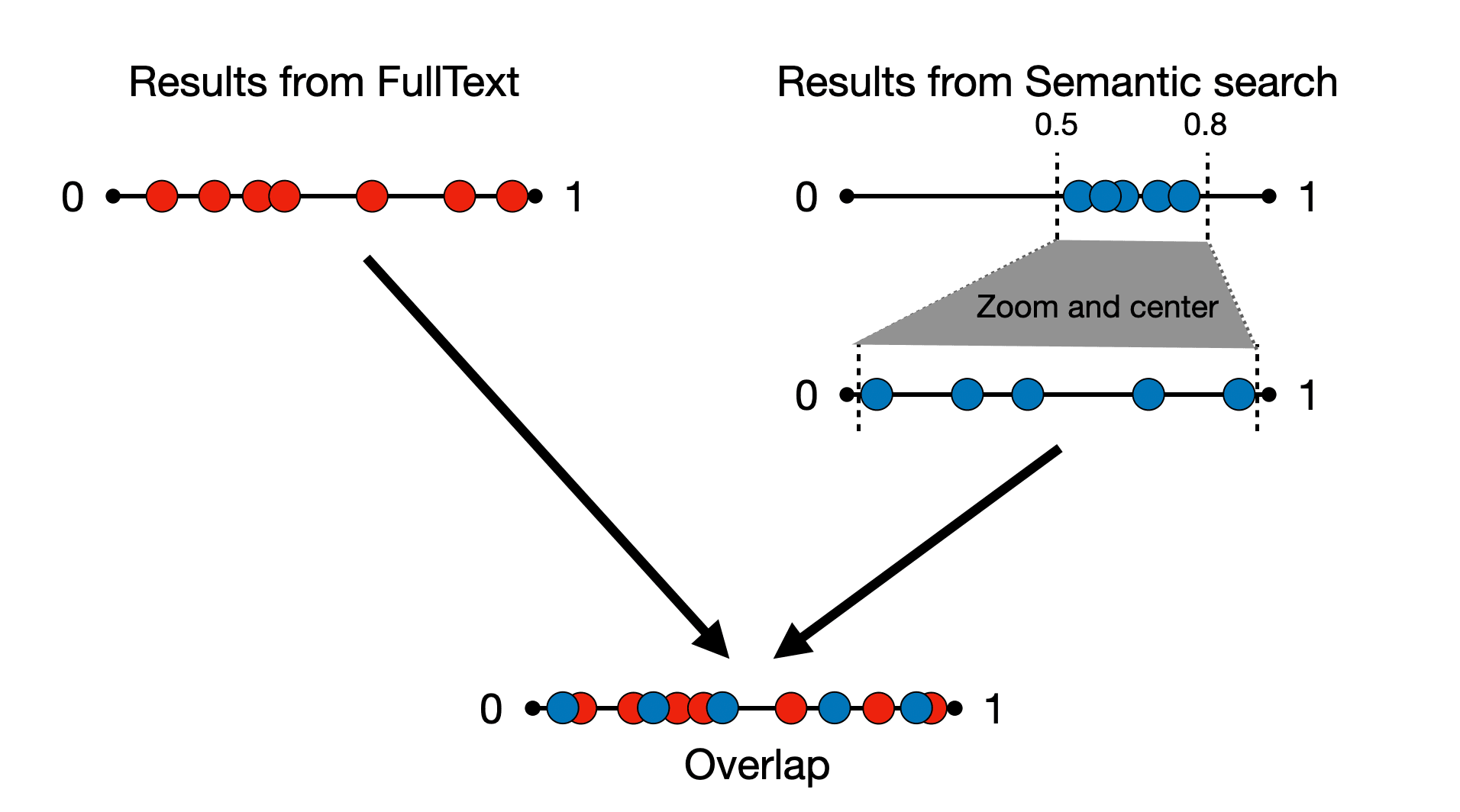 图2:语义搜索的结果经过拉伸(放大和居中),以便与全文搜索的结果结合。
图2:语义搜索的结果经过拉伸(放大和居中),以便与全文搜索的结果结合。
这种跨两种搜索类型的一致评分至关重要。它使您能够在查询时决定“语义比率”,即在组合语义结果和全文结果时,您希望赋予语义结果多大的权重。
混合搜索的优势:精确度和召回率
为了理解混合搜索的强大功能,我们简要回顾一下精确度和召回率的概念,这是信息检索中的两个基本指标。每个指标的重要性取决于具体问题。
想象你有一个电子邮件垃圾邮件过滤器
- 召回率衡量您的过滤器成功识别为垃圾邮件的所有真正垃圾邮件的百分比(这意味着实际进入您收件箱的垃圾邮件数量很少)。
- 精确度衡量您的过滤器标记为垃圾邮件的邮件中,实际是垃圾邮件的百分比(这意味着被错误发送到垃圾邮件文件夹的合法邮件数量很少)。
在数据库中搜索查询答案的背景下
- 召回率衡量我们成功检索到的所有相关文章(包含答案的文章)的百分比。
- 精确度衡量检索到的文章中实际包含答案的百分比。
让我们用一个数值例子来说明:假设我们有1000篇文章,其中100篇回答了“我需要哪些文件才能开办公司?”的查询。我们的搜索模型检索了90篇文章。在这90篇文章中,有60篇包含了查询的答案。
- 如果,在100篇相关文章中,我们的模型成功检索了60篇,那么召回率为60/100=60%。
- 如果在检索到的90篇文章中,有60篇包含答案,另外30篇不包含,那么精确度为60/90≈66.67%。
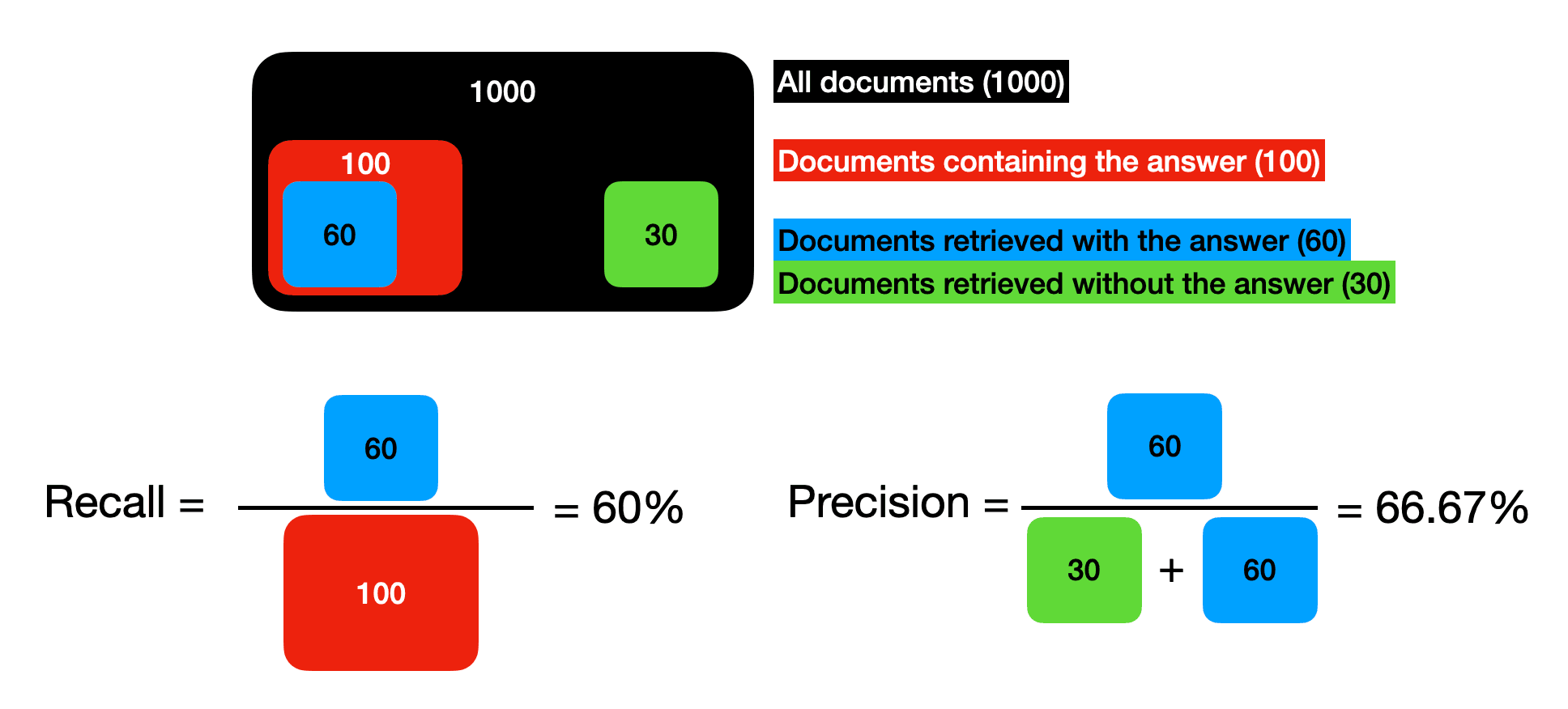 图3:精确度和召回率的例子。
图3:精确度和召回率的例子。
混合搜索与精确度-召回率
召回率:混合搜索显著增强了召回率。如果您的初始搜索效果不佳,重排序步骤无法神奇地解决问题;它只能重新排序它已获得的结果。我喜欢将其比作“泰坦尼克号上的甲板椅重新排列”,因为无论您如何重新排列结果,结果都不会好。混合搜索通过结合全文和语义方法的优势,有效地扩大了相关文档的初始池,从而构建了一艘更强大的船。
精确度:混合搜索也提升了精确度。全文搜索自然地提升了需要精确关键字匹配的查询的精确度,因为一篇包含许多精确词语重叠的文档很难无关。对于那些棘手的边缘情况,即文档可能与查询共享许多词语但主题不同,语义搜索就会介入,确保只有真正相关的文章才会被优先考虑。
通过智能地结合全文搜索和语义搜索的优势,混合搜索为信息检索提供了一种强大的方法,确保RAG系统能够访问最相关和最准确的信息,从而生成有洞察力和可靠的响应。在我们的下一篇博文中,我们将深入探讨整个RAG管道,并探讨Meilisearch如何简化其部署和维护。
优化性能:二进制量化和Arroy
除了混合搜索的核心逻辑之外,高效的向量管理对于大规模RAG系统至关重要。这就是二进制量化(BQ)的作用所在。BQ通过将32位浮点数转换为紧凑的1位表示,极大地缩小了向量嵌入,显著减少了磁盘空间和内存使用。简而言之,二进制量化通过只取符号来简化数字。例如,0.4、-0.5和0.6将被转换为+1、-1和+1。虽然这看起来像是一个宽泛的过度简化,但当我们处理数百或数千个条目的超长向量时,BQ确实大大加快了相似性计算,同时保留了大部分信息。
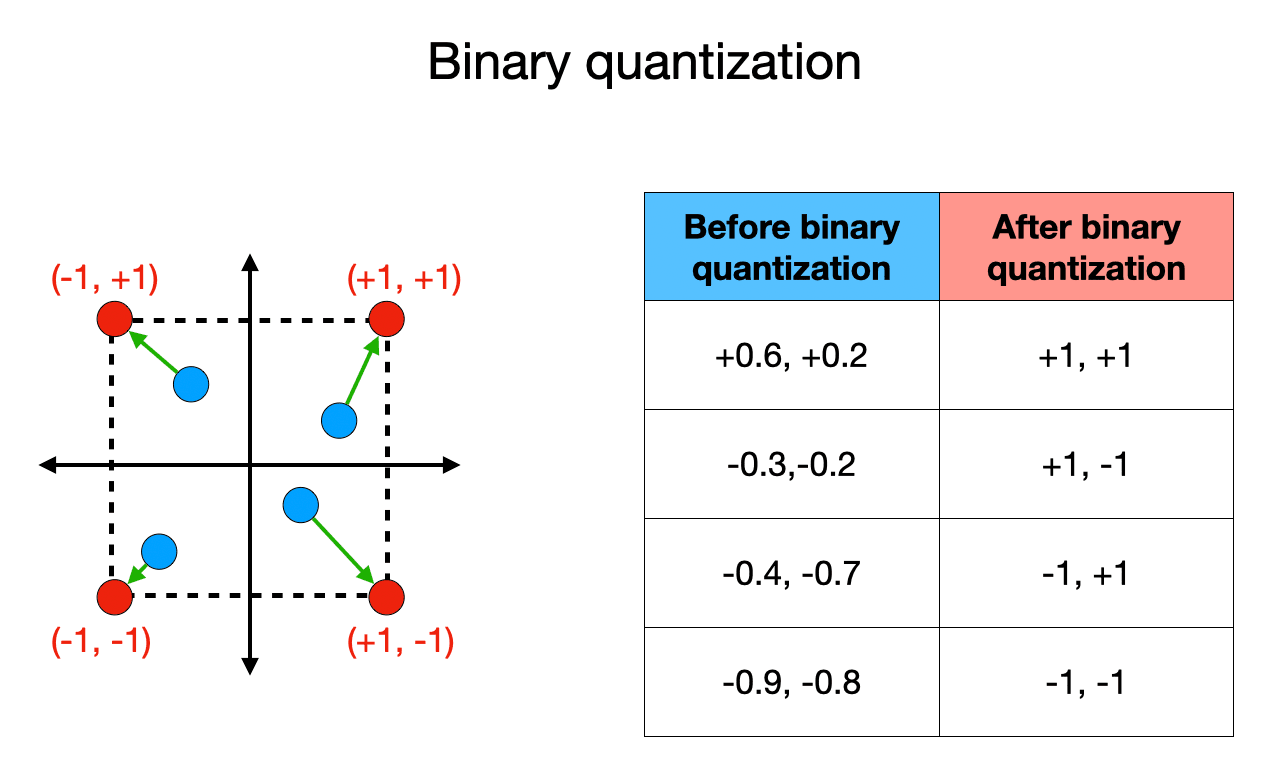 图4:二进制量化将数字转换为它们的符号,有效地将它们推到正方形的角上。请注意,点之间的距离略有变化,但计算变得简单得多。
图4:二进制量化将数字转换为它们的符号,有效地将它们推到正方形的角上。请注意,点之间的距离略有变化,但计算变得简单得多。
Meilisearch 还利用 Arroy,其基于 Rust 的向量存储,旨在实现高效的近似最近邻 (ANN) 搜索。最近邻搜索非常有效,但它可能非常慢,因为需要比较嵌入中许多文本片段之间的距离。Arroy 提供了几种加速技术,帮助模型“猜测”嵌入中最近的文章在哪里。
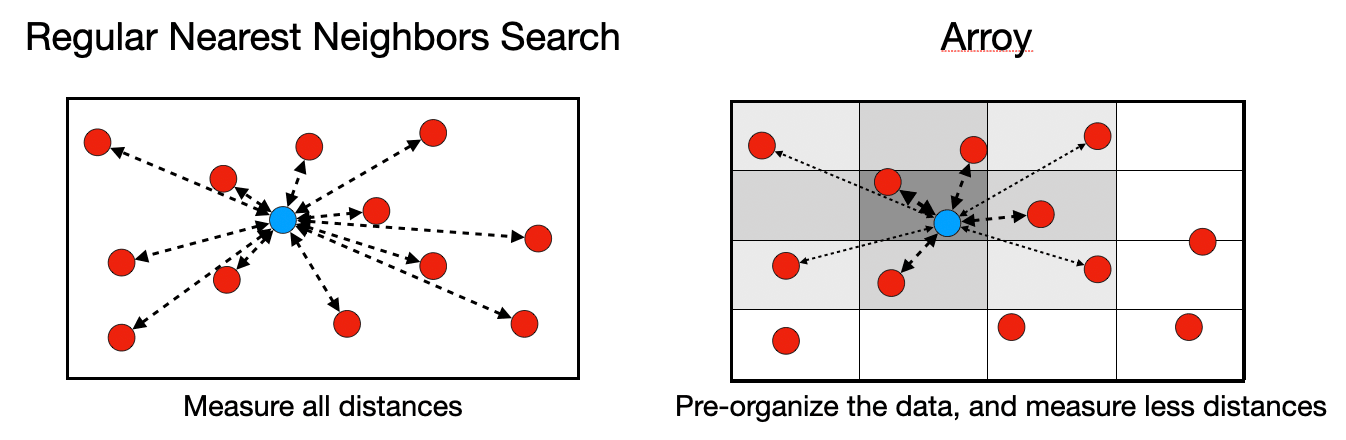 图5:常规最近邻搜索是有效的,但需要计算的距离太多。Arroy使用不同的技术来组织数据,因此需要计算的距离大大减少。在此示例中,使用了网格,并且只搜索相邻单元格,但通常,许多其他技术,包括基于树的技术,都用于组织数据,以实现有效和快速的最近邻搜索。
图5:常规最近邻搜索是有效的,但需要计算的距离太多。Arroy使用不同的技术来组织数据,因此需要计算的距离大大减少。在此示例中,使用了网格,并且只搜索相邻单元格,但通常,许多其他技术,包括基于树的技术,都用于组织数据,以实现有效和快速的最近邻搜索。
二进制量化和Arroy的强大组合使Meilisearch能够以卓越的索引速度和性能处理庞大的知识库,确保您的RAG系统即使对于高维嵌入也能提供快速、准确的答案。
立即探索Meilisearch的功能!
RAG的强大之处不仅在于LLM生成文本的能力,还在于其准确和相关的信息检索基础。正如我们所见,采用混合搜索,巧妙地融合了全文搜索的特异性与语义搜索的上下文理解,是克服幻觉挑战并提供精确答案的关键。借助Meilisearch,将这个关键的搜索层集成到您的RAG管道中变得异常简单,让您能够专注于构建真正智能的应用程序。
准备好用无与伦比的搜索相关性来增强您的RAG系统了吗?
立即探索 Meilisearch 的功能,并敬请期待我们的下一篇文章,我们将深入探讨如何使用 Meilisearch 构建完整的 RAG 管道,简化其部署和维护。

什么是 RAG(检索增强生成)及其工作原理?
RAG(检索增强生成)的完整指南。了解它的含义、工作原理、不同 RAG 类型、RAG 系统的组成部分等等。

